


一文读懂英伟达GTC:黄仁勋晒“AI核弹”,人型机器人也来了(组图)
牢牢掌握算力分配权的英伟达是人工智能领域当仁不让的“炸子鸡”。
通过为包括OpenAI、Meta等人工智能企业提供包括H200、H100、A100等不同规格的GPU,英伟达一跃成为全球市值增速最快的企业之一,也因此被外界称之为人工智能时代的“卖水人”。以至于黄仁勋和他的财务团队,会在财报中,通过直观的图表来说明英伟达对于业绩的自信。
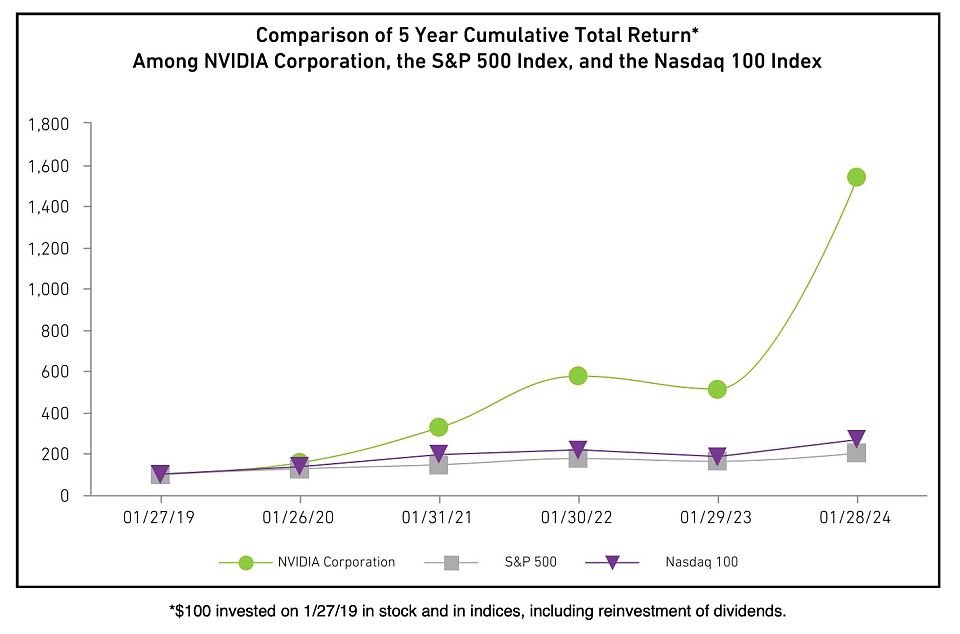
在向SEC提交的文件中,英伟达表示,2019年1月27日投资100美元(我们)的股票,2024年1月28日价值达到1536.28美元。而对应投资100美元标准普尔500指数和纳斯达克100指数基金,价值均在200美元以下。
今年的GTC2024上,黄仁勋的AI“核武库”正式上新,B200将成为科技巨头们追逐的“算力明星”——它不仅会成为新的AI算力底座,也将成为英伟达市值继续攀升的业绩底座。
作为NVIDIA Blackwell架构首款新产品,B200采用双芯片设计,晶体管数量达到2080亿个,基于Blackwell架构的B200,英伟达还提供了包括GB200、DGX GB200 NVL 72,以及基于GB200和B200打造的DGX SuperPOD超算平台。
软件服务方面,英伟达发布了集成AI开发软件微服务系统NIM,通过直接提供多行业、多模态的专有模型,以及基于NeMo Retriver的专有数据注入系统,企业可借由NIM快捷部署公司级专有模型。
除了通过软硬件赋能AI技术之外,英伟达也推出了加速AI仿生机器人落地的解决方案——GR00T机器人项目——世界首款人形机器人模型,支持通过语言、视频和人类演示,为机器人的生成行动指令。
以下为核心要点:
●B200芯片:采用双芯片设计,晶体管数量达到2080亿个。单GPU AI性能达20 PFLOPS(即每秒2万万亿次)。内存192GB,基于第五代NVLink,带宽达到1.8TB/s。
●DGX GB200 NVL 72:内置36颗GRACE CPU和72颗Blackwell架构GPU,AI训练性能可达720PFLOPs(即每秒72万万亿次),推理性能为1440PFLOPs(每秒144万万亿次)。
●基于GB200的DGX SuperPOD超算:搭载8颗DGX GB200,即288颗Grace CPU和576颗B200 GPU,内存达到240TB,FP4精度计算性能达到11.5EFLOPs(每秒11.5百亿亿次)
●Project GR00T:人型机器人项目——包含了人型机器人基础模型,ISAAC Lab开发工具库和Jetson Thor SoC片上系统开发硬件,带宽达到100GB/s,AI计算性能达到800TFLOPs。
●NIM软件:针对AI推理系统的新软件,开发人员可以在其中直接选择模型来构建利用自己数据的人工智能应用程序。
01 算力核弹B200
英伟达最近几代架构,在名称上都有致敬科学家的惯例。
上一代产品Hopper架构则是致敬格蕾丝·霍珀,这一代架构Blackwel则是致敬的是统计学家兼数学家大卫·布莱克韦威尔。

黄仁勋展示Blackwell和Hopper架构GPU对比,左边为Blackwell架构的B200芯片
在新一代的GPU正式亮相之前,关于架构、双芯片设计等已经有不少传闻,关注点在于,黄仁勋会把手中的“AI核弹”性能提升到多少?
现在,官方的答案给出来了——基于Blackwell架构的B200采用双芯片设计,基于台积电4nm工艺,晶体管数量达到2080亿个,上一代Hopper架构的H100同样是4nm工艺,但由于没有上双芯片设计,晶体管数量只有800亿。
B200搭配8颗HBM3e内存(比Hopper架构的H200多了2颗),内存达到192GB,基于第五代NVLink,带宽达到1.8TB/s,相比Hopper架构和Ampere架构,有了巨幅提升,最大可支持10万亿参数的模型的训练。
作为对比,OpenAI 的 GPT-3 由 1750 亿个参数组成,GPT-4参数为1.8万亿。

B200官方图
黄仁勋还介绍称,B200平台可以向下兼容,支持与上一代Hopper架构的H100/H200 HGX系统硬件适配。
此前,被称之为OpenAI劲敌的Inflection AI,官宣建立了一套22000颗英伟达H100 GPU的世界最大人工智能数据中心集群,接下来要看看OpenAI,能不能借助B200反超了。
这里再插一句英伟达的NVLink和NVLink Switch技术。
其中NVLink是英伟达开发的CPU和GPU之间高速互联通道,在内存墙无法突破的情况下,最大化提升CPU和GPU之间通信的效率,于2016年在基于Pascal架构的GP100芯片和P100运算卡上率先采用,当时的带宽为160GB/s,到H100采用的第四代NVLink,其带宽已经达到900GB/s,而B200采用的第五代NVLink 带宽已经突破1.8TB/s。
NVLink Switch支持与多个NVLink连接,实现NVLink在单节点、节点之间互联,进而创建更高带宽的GPU集群,基于最新的NVLink Switch芯片(台积电4nm工艺,500亿个晶体管),可实现576颗GPU组成计算集群,上一代产品仅支持到256个GPU。
根据官方公布的数据,B200支持第二代Transformer引擎,Tensor核支持FP4、FP6精度计算,单颗B200 GPU的AI性能达20 PFLOPs(即每秒2亿亿次)。

DGX版GB200 NVL72
另外,英伟达还在主题演讲中展示了全新的加速计算平台DGX GB200 NVL 72,拥有9个机架,总共搭载18个GB200加速卡,即36颗GRACE CPU和72颗Blackwell架构GPU(英伟达也提供了HGX B200版本,简单来说就是用Intel的Xeon CPU,替换了Grace CPU)。
黄仁勋说,一套DGX版GB200 NVL 72总共内置了5000条NVLink铜制线缆,总长度达到2公里,可以减少20kW的计算能耗。
举个例子,8000个GPU组成的GH100系统,90天内可以训练一个1.8万亿参数的GPT-Moe模型,功耗15兆瓦,而使用一套2000颗GPU的GB200 NVL72加速卡,只需要4兆瓦。
据介绍,DGX版GB200 NVL 72加速计算平台AI训练性能(FP8精度计算)可达720PFLOPs(即每秒72亿亿次),FP4精度推理性能为1440PFLOPs(每秒144亿亿次)。官方称GB200的推理性能在Hopper平台的基础上提升6倍,尤其是采用相同数量的GPU,在万亿参数Moe模型上进行基准测试,GB200的性能是Hopper平台的30倍。
演讲环节,黄仁勋还公布了搭载64个800Gb/s端口、且配备RoCE自适应路由的NVIDIA Quantum-X800 InfiniBand 交换机,以及搭载144个800Gb/s端口,网络内计算性能达到14.4TFLOPs(每秒14.4万亿次)的Spectrum-X800交换机。两者应对的客户需求群体略有差异,如果追求超大规模、高性能可采用NVLink+InfiniBand网络;如果是多租户、工作负载多样性,需融入生成式AI,则用高性能Spectrum-X以太网架构。
另外,英伟达还推出了基于GB200的DGX Super Pod一站式AI超算解决方案,采用高效液冷机架,搭载8套DGX GB200系统,即288颗Grace CPU和576颗B200 GPU,内存达到240TB,FP4精度计算性能达到11.5ELOPs(每秒11.5百亿亿次),相比上一代产品的推理性能提升30倍,训练性能提升4倍。
黄仁勋说,如果你想获得更多的性能,也不是不可以——发挥钞能力——在DGX Super Pod中整合更多的机架,搭载更多的DGX GB200加速卡。
02 NIM+NeMo:构建英伟达版企业用GPTs
英伟达的另一个杀手锏就是它的软件,它构成了这一万亿帝国至少半条护城河。
诞生于2006年的CUDA被认为是英伟达在GPU上建立霸权的关键功臣——它使得GPU从调用 GPU计算和GPU硬件加速第一次成为可能,让 GPU 拥有了解决复杂计算问题的能力。在它的加持下,GPU从图形处理器这一单一功能发展成了通用的并行算力设备,也因此AI的开发才有可能。
但谈论 NVIDIA时,许多人都倾向于使用“CUDA”作为 NVIDIA提供的所有软件的简写。这是一种误导,因为 NVIDIA的软件护城河不仅仅是 CUDA 开发层,还包含了其上的一系列连通软硬件的软件程序,比如英伟达开发的用于运行C++推理框架,去兼容Pytorch等模型训练框架的TensorRT;使团队能够部署来自多个深度学习和机器学习框架的任何 AI 模型的 Triton Inference Server。
虽然有如此丰富的软件生态,但对于缺乏AI基础开发能力的传统行业来讲,这些分散的系统还是太难掌握。
看准了这个给传统企业赋能的赛道,在今天的发布会上,英伟达推出了集成过去几年所做的所有软件于一起的新的容器型微服务:NVIDIA NIM。它集成到了不给中间商活路的地步,可以让传统企业直接简单部署完全利用自己数据的专属行业模型。

这一软件提供了一个从最浅层的应用软件到最深层的硬件编程体系CUDA的直接通路。构成 GenAI 应用程序的各种组件(模型、RAG、数据等)都可以完成直达NVIDIA GPU的全链路优化。
它让缺乏AI开发经验的传统行业可以通过在 NVIDIA 的安装基础上运行的经过打包和优化的预训练模型,一步到位部署AI应用,直接享受到英伟达GPU带来的最优部署时效,绕过AI开发公司或者模型公司部署调优的成本。Nvidia 企业计算副总裁 Manuvir Das表示,不久前,需要数据科学家来构建和部署这些类型的 GenAI 应用程序。但有了 NIM,任何开发人员现在都可以构建聊天机器人之类的东西并将其部署给客户。
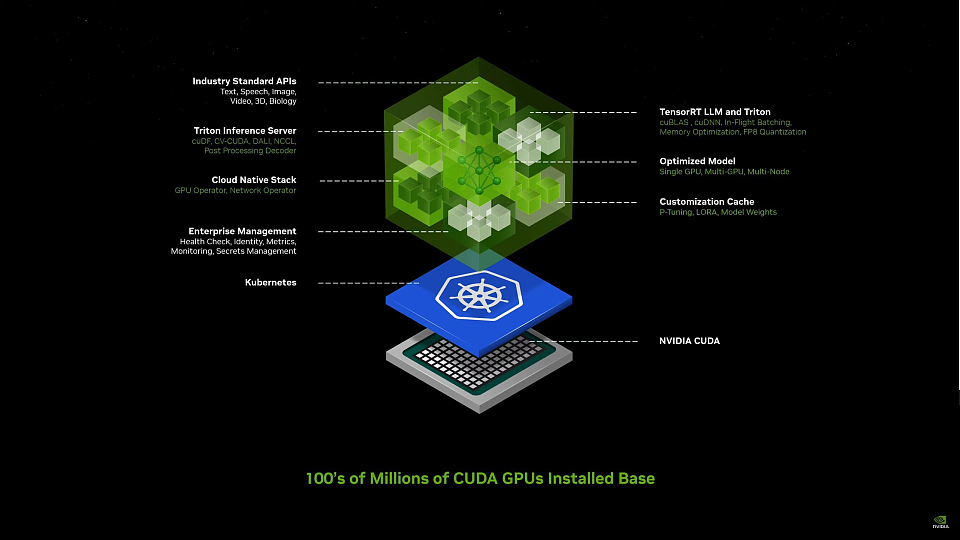
整合在Kubernets上的一揽子软件系统
这一切都建立在Kubernetes这一容器化应用程序之上。NVIDIA通过Kubernetes创建了一个单一的架构,可以运行所有这些软件。Nim作为预构建的容器(containers),开发人员可以在其中直接选择模型来构建利用自己数据的人工智能应用程序。在容器中配备了适用于语言和药物发现等人工智能领域的行业标准应用程序编程接口以适应各类专有模型。
英伟达在博客文章中表示:“NIM 针对每个模型和硬件设置利用优化的推理引擎,在加速基础设施上提供最佳的延迟和吞吐量。” “除了支持优化的社区模型之外,开发人员还可以通过使用永远不会离开数据中心边界的专有数据源来调整和微调模型,从而获得更高的准确性和性能。”
在模型支持方面,NIM 微服务的可选项也很多。它支持 Nvidia 自己的模型合作库,来自 AI21 Labs,Cohere等合作伙伴的模型,以及来自Meta、Hugging Face、Stability AI 和Google的开源模型。同时客户可以通过 Nvidia AI Enterprise 平台以及 Microsoft Azure AI、Google Cloud Vertex AI、Google Kubernetes Engine 和 Amazon SageMaker 访问 NIM 微服务,并与包括 LangChain、LlamaIndex 和 Deepset 在内的 AI 框架集成。这基本上就等于对所有市面上主流模型都完成了覆盖。
在Nim的搭建过程中,利用Nvidia NeMo Retriever技术,公司的专有数据都可以被集成到这个微服务里以供使用。最终用户会得到一个个NVIDIA NeMo,这就是针对每个公司的专有Copilit。这个专有的NeMo会用对话机器人的形式帮助你检索公司数据,如PPT,提供相关领域的技术支持。
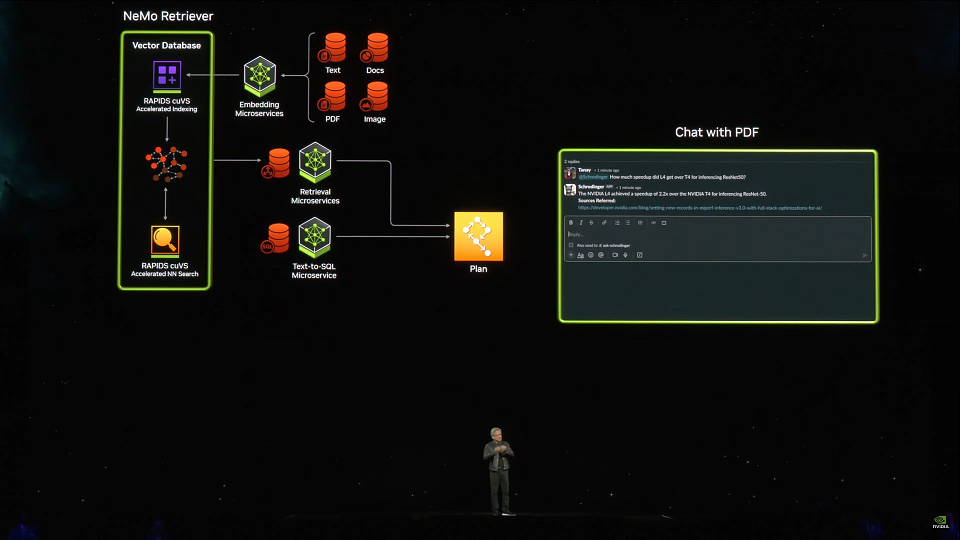
Nvidia NeMo Retriever与微服务的结合
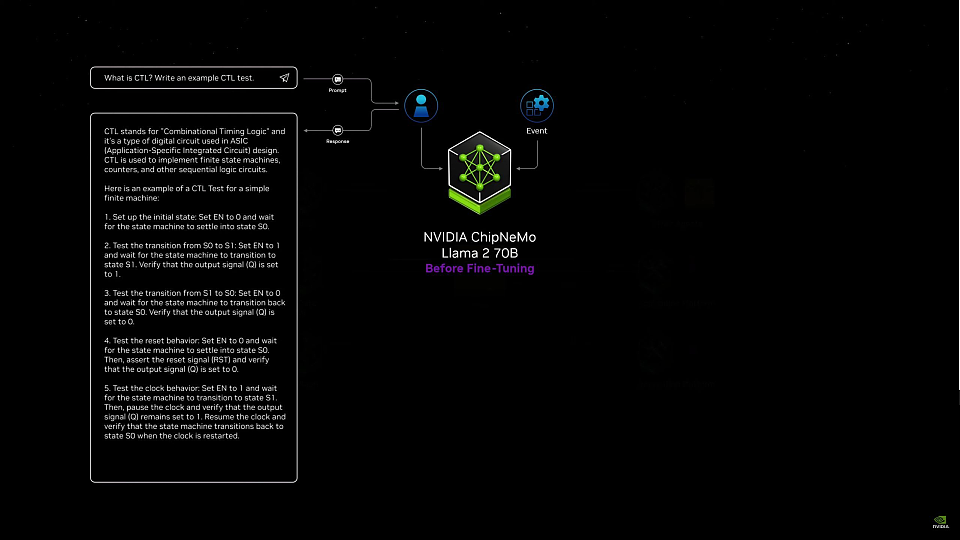
在发布会上,黄仁勋就展示了基于英伟达数据(Event)和芯片行业信息形成的Nvidia ChipNeMo,它构建在开源的Llama2模型之上。利用英伟达的专有数据,它可以回答只有英伟达公司内部使用的CTL实验细节问题。
这些NeMo还可以跨公司共用,也就是这套系统可以被视为工业大模型的GPT Store,行业公司可以使用其他公司或英伟达提供的行业基础NeMo添加自己的数据即可获得专有大模型。为此,英伟达还特意上线了ai.nvidia.com去承载这些NeMO。
这一微服务使得传统企业AI转型变得极为易得,不论是构筑专有模型,还是直接通过模型连接企业私有数据都变得快速方便。黄仁勋表示 “成熟的企业平台坐拥数据金矿, 他们掌握了大量可以转化为副驾驶的数据,当你准备好运行这些人工智能聊天机器人时,你将需要一个人工智能铸造厂”。NIM正是这样一个铸造厂。它帮助构建企业AI转型的Copilot级产品,可以被视为公司AI化所需的基石。
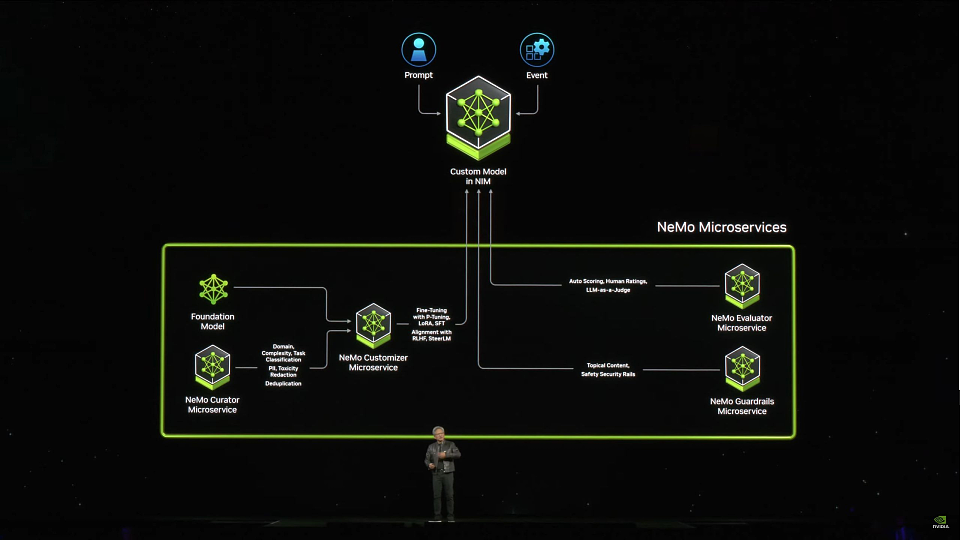
NeMo微服务的整体架构
这一产品将首先在即将发布的NVIDIA AI企业版第五版中搭载。对于NVIDIA AI企业版的现有客户来说这只是一个软件升级。这项新功能不会额外收费。当然企业版价格本身并不低,单GPU的企业版使用权限包年就需要4500美金,小时租金为1美金每小时。
目前英伟达全公司已经都用上了Nim,包括Box、Cloudera、Cohesity、Datastax、Dropbox等合作伙伴也都已经参与Nim的使用和优化过程。
03 Project GR00T机器人
英伟达的上一个万亿市值来自GPU与算力,下一个万亿市值增幅空间可能体现在对机器人开发的赋能上。
年初,英伟达资深科学家Jim Fan就宣布建立GEAR工作室,相关研究成果以及研究基础环境成为了英伟达新机器人解决方案的基础。
据了解,英伟达目前正在构建包括NVIDIA IAI、Omniverse、ISAAC三大平台,三大平台均与机器人产业高度关联。其中NVIDIA IAI搭载DGX系列产品,用于模拟物理世界,Omnivese搭载RTX和OVX系列产品,用于驱动数字孪生的计算系统,ISAAC搭载AGX系列,用于驱动人工智能机器人。

黄仁勋在现场介绍基于英伟达解决方案开发的人形机器人产品
本次GTC大会上,英伟达还推出了Project GR00T人型机器人项目——人型机器人基础模型。
英伟达表示,基于GR00T人型机器人基础模型,可以实现通过语言、视频和人类演示,来理解自然语言,模仿人类动作,进而快速学习协调性、灵活性以及其他的技能,进而能够融入现实世界并与人类进行互动。
除了基础模型,该项目还包括基于NVIDIA Thor SoC系统的开发套件Jetson Thor,内置了下一代Blackwell GPU(此前英伟达也推出个针对汽车的DRIVE Thor套件),带宽达到100GB/s,AI计算性能达到800TFLOPs。
为了给Project GR00T项目提供软件支持,基于英伟达Omniverse构建的ISAAC Lab也进行了同步更新,允许开发者利用该平台模拟机器人学习技能、与物理世界模拟互动,支持数千个机器人同步训练与模拟。
与此同时,ISAAC Lab还整合了用于辅助提升机械臂的灵敏度与精确度的加速库平台ISAAC MANIPULATOR,以及用于提升服务机器人感知能力的ISAAC PERCEPTOR软件库。

现场演示基于Isaac Lab开发库实现的人机交互
按照惯例,英伟达也不免俗的用了客户的例子为自家解决方案背书——比亚迪仓库机器人。
黄仁勋表示,英伟达过去和比亚迪基于Omniverse构建汽车和工厂数字孪生上有了良好的合作,当然也还包括汽车自动驾驶业务方面的合作,现在则开始基于英伟达的ISSAC,展开仓库自动机器人研发方面的合作。
在英伟达的愿景当中,未来Omniverse将成为机器人系统的诞生地和AI的虚拟训练场,你可以将其理解为“机器人产房”、“AI驾校”。
04 气象观测、计算光刻与6G
Omniverse的模拟不仅仅体现在机器人、数字孪生领域,在一些新技术的研发上,比如代表未来通信的6G技术研发也将派上用场。
根据官方公布的信息,英伟达将推出6G研究云平台,其中包括为开发人员提供神经无线电仿真框架能力的NVIDIA Aerial,以及提供模拟城市规模网络的Omniverse数字孪生系统,以及提供加速的无线接入网络堆栈,从系统层面为开发者模拟一个具有城市规模的6G网络系统。
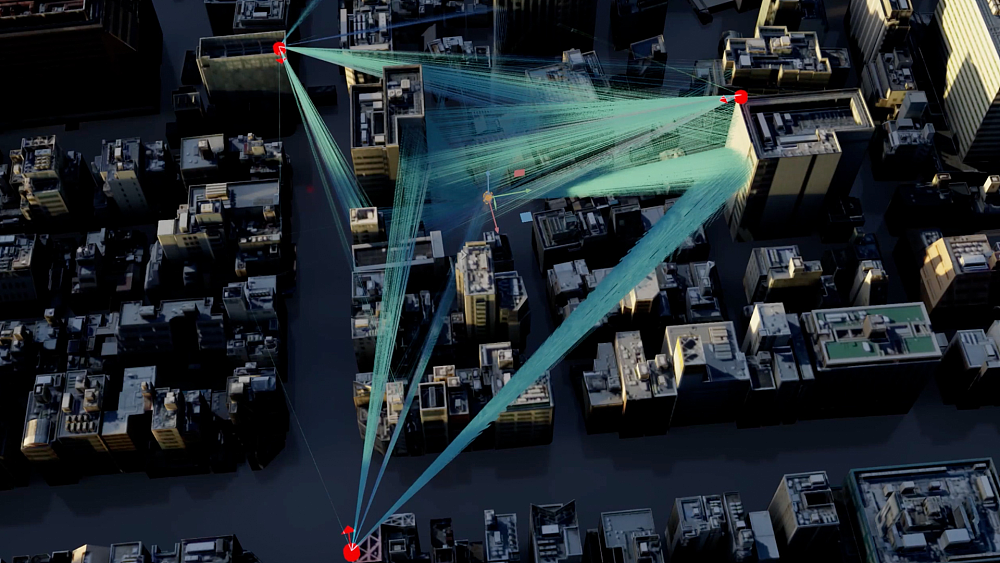
基于英伟达6G云平台,开发者可以模拟城市大规模无线网络环境
除了6G研究,英伟达希望将Omniverse带到气候和天气预测方面。
官方表示,极端事件每年为全球带来了1400亿美元的经济损失,而目前高性价比的气候模拟高度不能满足需求,虽然千米级的模拟可以帮助人类模拟预测气候和天气,但这个计算量相比高空模拟要超出100万倍,进而成本高昂。
为此,英伟达公布了地球气候数字孪生套件NVIDIA Earth 2,它具有可交互的特点,支持通过高分辨率模拟来加速气候、天气预测。作为一个支持千米级天气预测的AI扩散模型,Earth 2在天气预报的计算预测上效率提升达到1000倍,而能效则提升了2000倍。
GTC2023大会上,英伟达推出计算光刻CuLitho软件库,按照当初的设想,单就晶圆厂部分的提效即可以实现,每天利用1/9的电力,生产3-5倍的光掩膜,今年的大会上,黄仁勋也补充了计算光刻CuLitho的进展。
官方表示,过去12个月内与TSMC和Synopsys紧密合作,已经将CuLitho集成这些客户的工作流当中,包括芯片的设计工具和生产制造。









 +61
+61 +86
+86 +886
+886 +852
+852 +853
+853 +64
+64


