


AI能耗之困:微软的核能赌注,能否拯救智能未来?(组图)
最近,在AI领域,微软搞了个大动作,他们打算用核能来给他们的AI项目供电。
是的,你没看错,就是核能。

主要原因,是AI大模型的训练、推理,实在太耗电了。
据《华尔街日报》报道,微软正在计划利用下一代核反应堆,即所谓的
小型模块化反应堆
(SMR),来支持其数据中心和AI项目。
不过,现实情况却是,随着核电站的关闭速度超过新建速度,全球核电产量继续下滑。
而且由于政治、监管和经济等一系列原因,目前还没有一个西方国家开始建造SMR。
在这种情况下,微软决定当第一个“吃螃蟹”的人,也是为了保住自身在AI领域的龙头地位。
在最近 OpenAI的CEO 萨姆·奥特曼公布的2024年计划表中。人们赫然发现了GPT-5的字样。
可是,要想追求更强大的AI,就必须有更充足、强大的能源。
这点从之前各种AI大模型的耗电量中,就已经得到了显现。
先是 Huggingface 自家的 BLOOM 大模型,有 1760 亿参数,光是前期训练它,就得花掉 43.3 万度电。这相当于大约2082个中国家庭(而且还是三口之家)一个月的用电量。
而最近发表在《焦耳》杂志上的一项研究表明,到2027年,生成式人工智能所消耗的能源能为荷兰大小的国家提供一年的电力,相当于约85-134太瓦时(TWh)。
这就引发了一个关键的问题:要想真正实现AGI(通用人工智能),人类在能源方面,究竟要付出多大的代价?
01
能源深坑
AI造成的“能源深坑”究竟有多难填?
中国工程院院士、阿里云创始人王坚曾打了这么一个比方——
过去一百年里,全球电动机消耗掉的电量就占到了总发电量的一半,而现在的大模型就相当于新时代的电机。
研究机构New Street Research估计,仅在AI方面,谷歌就需要大约40万台服务器,每天消耗62.4吉瓦时,每年消耗22.8太瓦时的能源。
而立陶宛或斯洛文尼亚这样的小国,全年的用电总量也不过在10+太瓦时左右。
也就是说,仅谷歌在AI方面的用电量,就毫无压力地碾压了两个人口数百万的小国……
而AI大模型之所以如此耗电,一个重要的原因,就是其必须从大量数据中“学习”和提取深层次的规律或知识。

AI模型训练,就像是在教电脑学会理解和处理非常复杂的问题,比如学会一种新语言、识别成千上万张图片里的物体,或者预测天气变化。要做到这一点,大模型需要通过查看和分析成千上万甚至上亿的例子(数据)来“学习”。
由于无法像人脑一样“举一反三”,这样的计算,往往需要涉及到模型内部的数十亿甚至数千亿的参数。
打个比方,这就好像参加一场复杂的数学考试,人脑仅需一本教材,消耗一个肉包子,就能考60分,而AI可能要啃1亿本教材,耗费上万度电,才能勉强接近人类的水准。
而为了追求更强大的性能,以现阶段的技术路径,人们往往只能持续不断增大模型的参数。例如之前的GPT-3.5是1750亿,GPT-4为1.8 万亿,而去年11月,亚马逊发布的全新大模型
Olympus
,参数更是达到了2万亿。
随着模型的复杂度和规模不断增长,AI对算力的需求也在迅速增加。而用于训练的GPU,也会随之遇到性能瓶颈,从而达到其能效的物理极限,导致功耗显著增加。
而所谓“能效的物理极限”,指的是GPU在每消耗一定量的电能时,能够完成的最大计算量。
这就像是一辆汽车在每公升油能行驶的最远距离。当GPU接近或达到这个极限时,要想进行更多的计算,它们就需要更多的电力。

这就像是一台已经非常节油的汽车,要增加行驶距离,就必须加更多的油(电力)。以目前的AI服务器DGX A100为例,其搭载的8颗A100 80GB GPU,最大系统功耗达到了6500W。
除了训练阶段外,模型的推理,也是一个持续消耗电力的过程。
芯片研究公司SemiAnalysis研究报告称,使用大模型进行问题搜索所消耗的能源是常规关键词搜索的10倍。
倘若标准Google搜索消耗0.3瓦时的电量,而与大模型每次互动的耗电量为3瓦时。如果人们每次在谷歌搜索都使用AI工具,每年大约需要29.2太瓦时的电力。
这相当于给全球最大的摩天大楼,迪拜的哈利法塔,连续供电超过300年。
这些炸裂的数据,也让人想到了一个细思极恐的事实,那就是:倘若目前仅一万多亿参数的GPT-4这类模型,耗电量就如此可怕,那将来更强大的GPT-5,或是其他更先进的模型,耗电量又会是什么地步?

一个可以预见的事实是:只要目前的大模型,继续沿着“参数越大,能力越大”的技术方向走下去,那么下一代更强的通用模型,在能耗上必然是倍增的。
照这样来看,人类通往AGI的道路,会因为“电力匮乏”而被锁死吗?
02
SMR
面对这样的电力困境,AI巨头微软直接来了个“大招”——上核能!
这才有了我们开头提到的新闻。
微软打算建造的这个小型核反应堆(SMR),也可以被看做大号的“核电池”,使用的还是核裂变技术,每台SMR反应堆发电装机容量不超过300兆瓦,不到传统核反应堆装机容量的三分之一。
但由于小型化、模块化的特点,其部署起来灵活方便了很多。

现在在美国,想搞个商用的SMR,过程和难度都会让人焦头烂额。
原因就在于,其审批手续实在是太严苛,太复杂。
目前整个美国只有
NuScale Power
一家公司拿到了SMR的监管批文。
而光是为了拿批文,NuScale在整个审批过程就花费了超过5亿美元,总共提交了1.2万页的申请表,相关的文件、材料则超过200万页……
既然如此,那微软为什么依然“头铁”地想要搞SMR呢?
最核心的原因主要有两点。
首先一点,就是之前提到的大模型“参数越大,能力越大”的桎梏。在这样的技术路径下,模型性能每提升一个层次,其参数和消耗的电能,也会随之倍增。
咨询机构Tirias Research曾预测,到了2028年,数据中心功耗将接近4250兆瓦,比2023年增加212倍,数据中心基础设施加上运营成本总额或超760亿美元。
于是,在这种电力和模型功耗“你追我赶”的趋势下,化石燃料的成本、能量密度的瓶颈很快就会显现。

而SMR的出现,则为这种看似无止境的“追赶游戏”,画上了一个暂时的休止符。
因为与传统的化石燃料相比,甚至与一般的大型核电站相比,SMR最大的优势之一,就是无需频繁地更换燃料。
与传统核电厂1~2年换料周期相比,基于SMR的发电厂换料频率低,可以每3~7年进行一次燃料更换。甚至一些SMR设计可在不更换燃料的情况下运行长达30年。
而SMR之所以那么“耐用”,主要是因为SMR通常使用更高富集度的低浓缩铀(LEU)燃料。这意味着燃料中铀-235的百分比高于传统的核电站使用的LEU。高富集度的燃料可以提供更高的能量密度,从而延长燃料循环的长度。
而相较之下,大型核电站的核心设计和操作参数,通常是基于传统的低富集铀燃料(通常为3%到5% U-235)进行优化的。这些设计限制决定了大型核电站的燃料循环效率。
正是这样“干得多,吃得少”的特点,让SMR在长期运营的过程中,拉开了与化石燃料的成本差距。
除了长期成本的考虑外,微软选择SMR,也是在美国能源大战略下的一种决定。

当前,拜登政府将能源战略重点放在了清洁能源革命上。2021年11月,拜登推动国会两院通过《基础设施投资和就业法案》,向能源领域投资约620亿美元。目标是在2035年前实现美国的无碳电力。
实际上,在当前碳中和和全球能源转型的大背景下,可再生能源与化石燃料之争,已经不仅仅是一种成本、效率的问题,而是意味着世界工业又进入了大变革时期。
纵观工业革命的历史,这类变化不仅会带来海量“发财”的机会,也会在某种程度上重塑世界权力的格局。
毕竟,在第二次工业革命时,美国正是在内燃机的发明和汽车的普及的背景下,因其在石油生产和加工方面的领先地位,一跃成为了工业强国。
而在现在这个能源转型的路口,美国为在清洁能源领域确立自身的优势,也开始出台各种政策,扶持可再生能源,抑制碳排放。
例如在碳税方面,民主党参议员怀特·豪斯在2021年提出了《清洁竞争法案》(Clean Competition Act,简称CCA)。

从2024年开始,不论是美国产品还是进口产品,如果碳含量超过基准线,就对超出部分征收55美元/吨的碳税,这个碳税标准每年上浮5%。
虽然CCA主要针对的是能源密集型的初级产品(如石油、化肥、水泥等),并不直接针对AI大模型这种无形的、虚拟的软件产品,但只要大模型的发电,离不开传统的化石燃料,微软就必须一直承担这额外的“碳税”。
且由于之前提到的模型参数的“递增效应”,这部分碳税将来可能会像滚雪球一样越来越大。
然而,诡吊的是,尽管能源转型推进得如火如荼,但在核能问题上,美国以及整个西方,都是一种直摇头的态度。
还记得之前提到的那个为了通过SMR审批,提交了200万页材料的 NuScale Power吗?目前微软也面临了类似的“审批窘境”。
有了NuScale Power这样的“前车之鉴”,微软在申请SMR时,甚至干脆专门训练了一个用来应付文件审批的大模型,用来处理数量可怕的审批文件……

至于西方为何在核能态度上如此保守,这其中的原因,实在太复杂了,涉及到成本、安全、政治等一系列因素。
但总的来说,在多种因素的综合作用下,西方的核能政策已经形成了一种巨大的惯性,短时间内难以掉头。
因此,微软使用SMR来为AI发电的想法,虽然看似雄心勃勃,但从现实层面上说,其现阶段仍然只是一种“远水”,难以解决AI能耗危机的“近渴”。
03
类脑芯片
既然用核能来为AI发电这条路,现阶段是很难走通了,那人类要想触及更强大的AI,是否还有别的途径呢?
一个可能的办法,就是在AI运行的硬件上下手,把AI消耗的电力“省”回去。
而在这方面,目前业内有两个比较主要的技术路线,其中一种已经投入使用的,是用先进封装技术,把CPU,GPU,FPGU,RAM等等单元组合在一起,例如英伟达的H100、H200就是这类路子。
这些GPU采用了英伟达的Hopper架构,通过将多个芯片集成到一个封装中,可以显著减少物理尺寸,从而让集成的芯片之间通过短距离的互连进行通信。

这样的设计,这比传统的PCB上的长距离通信要快得多,由于数据在芯片之间的传输速度更快,延迟更低,因此整体系统的功耗也变得低了很多。
然而,这样的思路,仍然是通过优化现有技术来提高能效,而如果想在功耗方面出现全新的、革命性的变化,人类就需要一种更加颠覆性的硬件设计。
这就要提到另一个主要的技术思路:是让训练AI的芯片,在结构上越来越“像”人脑。
毕竟,与现在功耗巨大的GPU、TPU相比,人脑着实算得上是一个低功耗,但却十分高效的智能系统。
大脑的运行功率约为12至20W,相当于身体代谢率的20%,完成一场复杂的数学考试,人脑所需的能量,与一盏节能灯相当,而AI大模型却要消耗数百瓦的电能。
而这种能够像人脑一样思考的硬件,就是基于神经拟态(Neuromorphic)技术的“类脑”AI 芯片。
这种芯片最大的意义,就在于其通过模拟人脑神经元的构造,解决了AI计算过程中“存算一体”的问题。

具体来说,现在AI计算中大量的能量消耗在了计算和存储单元之间搬运数据中,而人脑却并非如此。
人脑中的信息不是集中存储在某个特定位置,而是分散在神经元网络中。这种并行处理机制允许大脑在不依赖类似“CPU”的中心的情况下,同时处理大量的信息。
这种分布式的计算方式,减少了对单一“中央处理器”的依赖,从而降低了整体的能耗。
而神经元和各个突触之所以能相互连接,各自为战,是因为这些突触可以调整其连接强度,即突触的可塑性。
而这种可塑性,允许突触在存储信息的同时参与计算过程,这就相当于芯片中的“存算一体”功能。
对应到了
NPU
这里,模拟神经元和突触的原件,就变成了忆阻器(memristor)。

简单来说,在忆阻器阵列中,每个忆阻器可以模拟一个突触,通过改变其电阻状态来模拟突触的强化或弱化,从而降低AI计算中的功耗。
打个比方,忆阻器就像是一个可以改变孔大小的神奇水箱。当你给忆阻器通过电流(就像给水箱施加压力),忆阻器的“孔”就会变大或变小,这个孔的大小决定了水流(电流)的通过的难易度,就像人脑中神经突触的强度,决定了信号传递的速度一样。
在传统的计算机系统中,存储和计算是分开的。就像你需要将水从水箱搬到另一个地方来控制水流一样,数据需要在存储器和处理器之间来回传输。这个过程需要能量,就像搬水需要力气一样。
但是,忆阻器的神奇之处在于,它可以直接在存储信息的地方进行计算。就像你可以在水箱内部调整孔的大小来控制水流,而不需要搬水一样,忆阻器可以直接改变其电阻状态来模拟计算过程,这样就减少了数据传输的需要,从而降低了能量消耗。

对于类脑芯片来说,忆阻器是极其关键的部分,但制造起来难度也颇大。
由于忆阻器的电阻值依赖于过去通过的电压,这种记忆效应对制造过程高度敏感。而目前制造忆阻器使用的材料,如二氧化钛存,还存在各种物理缺陷,这会引入电参数的不确定性。
更重要的是,从现实层面上来说,在人们苦心打造类脑芯片时,AI卖铲人黄仁勋也不会闲着,过去数年来,随着GPU性能的不断增长,在AI计算领域已经形成了一种“黄氏定律”。
这一“定律”认为,GPU在AI计算能力上的增长,会远超过摩尔定律,以每两年提升1000倍的速度快速发展。
按照老黄的估计,这种指数级增长会持续存在。即使类脑计算在某些方面具有潜在优势,但面对GPU“黄氏定律”的发展速度,以及GPU拥有的成熟的软硬件生态(例如英伟达的CUDA),忆阻器显然像是一种更加遥远的技术。

有鉴于此,在通往AGI的道路上,人类要想跨过能源这一难关,还是得找别的更现实、更靠谱的路子。
04
能源“组合拳”
在可预见的未来,一种切实可行的,能够明显降低AI能耗的技术路径,或许并不是某种单一的能源或硬件技术,而是基于大模型自身结构的变化所形成的一套“组合拳”。
具体来说,这套“组合拳”可总结为:模型压缩——转移端侧——反哺和优化能源。
这几大步骤之间,可以说环环相扣,互为依赖。
首先,所谓的模型压缩,是指在尽量保持模型性能、优势的情况下,尽可能地缩减模型的参数。
参数小了,训练、推理所需的功耗自然就降了下来。
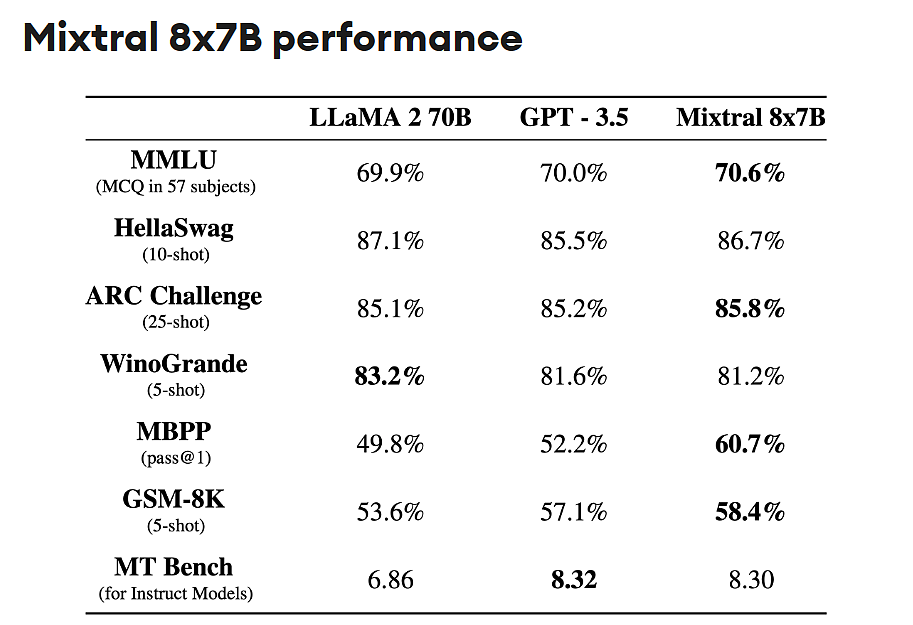
在这方面,欧洲团队发布的Mixtral8x7B、微软发布的Phi-2等模型,就是这类小型化技术的典型代表。
以Mixtral8x7B为例,这是一种采用了稀疏混合专家模型(SMoE)技术,结合了多个针对特定任务训练的较小模型,在许多基准测试中,Mistral 8x7B的性能已经达到甚至超越了规模是其25倍的Llama2 70B。
同样的,微软推出的Phi-2虽然规模更小(仅27亿参数),但得益于“教科书质量”数据的训练,以及学习其他模型传递的洞见的技术,目前已在某些基准测试中超过了更大的模型,如 70亿参数的Mistral和130亿参数的Llama2。
经过压缩之后,这些“小而精”的模型,就能够被移植到各种边缘设备,如手机、平板、物联网(IoT)设备、自动驾驶汽车和无人机中。
而这又是组合拳中降低AI功耗的另一个关键。
对于AI大模型而言,要想真正走出,进入到更广的场景,进入各种边缘设备是必然的趋势。
之前,在模型参数量巨大时,边缘设备受制于其硬件性能,往往只能通过云端运行。
但从去年年末AI硬件集体发力的情况来看,2024很有可能是边缘侧AI集中爆发的一年。
去年12/14,英特尔举办“AI Everywhere”发布会并推出新一代面向AI PC的酷睿Ultra处理器产品Meteor Lake。AI落地PC终端趋势下,AMD Ryzen 8040系列、高通X Elite等PC处理器均集成NPU,“CPU+GPU+NPU”组合已成为AI PC处理器主流架构。

当模型压缩,且各种端侧芯片的性能提升后,各个边缘设备就能在本地直接运行模型,而无需调用云端(数据中心)的算力。从而降低了AI的总负载和能源消耗。
更巧妙的是,在进入边缘设备后,这些小型化了的端侧模型,还能反过来给AI加一层节能BUFF,进一步降低其能耗。
在能源行业中,边缘设备,或端侧设备,主要是指各种各样的传感设备,利用AI的边缘推理能力,端侧模型能在设备上进行实时的反馈、分析,给出度电成本最优的可调负荷,就能将电网的负载与能耗保持在最优水平。
具体来说,AI系统通过边缘设备(如智能电表、传感器)实时收集电力系统的运行数据,包括能源的生成、传输和消费情况,并通过持续收集和分析电力系统运行数据,不断学习和理解系统的运行模式。
例如,AI可以学习到不同时间段的用电需求变化,以及天气条件下的可再生能源的供应模式。
例如,一家名为Envision Energy的能源公司在设计和制造智能风力发电机时,在每个发电机上,通过安装的 500 多个传感器。收集了关于运行,发电,怎样维护等数据。

等收集到的数据被积累,新的模式和见解就开始涌现。通过监测风速和风向等因素,适当地对风力发电机的叶片的间距,进行实时调整,风电场可以将产量提高约 15%。
在这套组合拳的攻势下,将来人们应对AI这头吃电的怪兽,可能就会形成一种“农村包围城市”的策略。
“农村”象征着数量众多,且部署在边缘的AI小模型,通常情况下,它将满足大部分人日常的AI需求,并分担数据中心的大量能耗。
而被包围的“城市”,则象征着参数量巨大的大模型,及其所代表的高性能计算场景。
在这样的格局下,小模型将满足人们日常用AI写作、生图一类的琐屑工作,而参数更多的大模型,将担当起领头羊的角色,通过不断训练和改进,拔高AI智能的上限,同时在
可控核聚变
、类脑芯片等潜在手段的辅助下,带领人类向着AGI时代不断迈进。
结语
关于“电力之困”是否会锁死人类通向AGI的道路,在结尾,可以试着用凯文·凯利的作品《技术想要什么》中的“三元理论”来分析一下。

凯文·凯利曾言:科技如同人的个性,由三元力量塑造而成。首要的推动力是预定式发展——科技自身的需求。第二种动力是科技史的影响,也就是旧事物的引力,就像马颈圈的尺寸决定太空火箭的尺寸那样。第三股力量是人类社会在开发技术元素或确定选择时的集体自由意志。
在这三种力量中,前两种是相对明确和固定的,最大的变量,就是人类的集体自由意志。
不同的政策与法规、消费者选择和市场力量,乃至各异的价值观和文化,都会影响AI发展的方向和速度。
具体来说,谷歌微软这样的巨头,作为AI行业的引领者,其AI产品和技术方向,无疑影响了大批的后来者。
然而,这些巨头的在AI方向上的定位,都是冲着制霸全球市场的格局去的,因此其一个劲儿地堆模型参数,甚至不计代价地搞核能,也是情理之中的事。
可问题是,并不是每一个企业,都有必要对标或“超越”GPT-4这类顶流AI,而GPT-4本身也并非完美无缺。

例如,最近曝出的一则新闻中,就提到了GPT-4目前正不断“变笨”,以至于OpenAI正考虑将其重新训练。
因此,与其一味地跟风、炒作,或是搞些只有纸面意义的“刷榜”、“测评”,倒不如冷静地从大众需求,从客观实际出发,针对性地开发人们需要的AI应用,减少重复、无效的模型训练,对大部分企业而言,才是现阶段摆脱AI“能耗陷阱”的一种明智做法。
并且,从科技本身的角度来说,一个充满多样性、差异化的技术生态,才是真正健康和有活力的。
毕竟,在当前生成式AI技术尚无统一理论范式的情况下,谁也不能确定谷歌、微软这类巨头的路线,就是通往AGI的“正道”,既然如此,何不多保留一些可能性?








 +61
+61 +86
+86 +886
+886 +852
+852 +853
+853 +64
+64


