


人类1:10惨败 5分钟崩盘 “狗弟”横空出世(组图)
继围棋之后,强大的人工智能(AI)在北京时间25日凌晨再次震撼世界:
图片来源:DeepMind博客
仅仅5分钟,谷歌旗下的人工智能公司DeepMind开发的全新AI程序AlphaStar就让《星际争霸2》(以下简称星际2)职业选手MaNa投降。

而TLO的说法跟李世石输给AlphaGo后很像。他说:相信我,和AlphaStar比赛很难。不像和人在打,有种手足无措的感觉。他还说,每局比赛都是完全不一样的套路。
赛后,DeepMind在其官方博客上表示, 实现最高水平的星际2对弈代表了人工智能在有史以来最复杂电子游戏中取得的重大突破。AlphaStar背后的技术可以用来解决其他的问题, 比如天气预报、气候建模、语言理解等。
让AI玩星际争霸有多难?
暴雪出品的星际2近年来已被公认为AI研究的“大挑战(grand challenge)”。与下围棋相比,星际2可难得多——在围棋世界,动作空间只有361种,而星际2大约是10的26次方。
DeepMind也在其官方博客上解释了人工智能玩星际2的难点:
游戏理论:星际2是个游戏,就想剪刀石头布一样,没有单一最佳战略。因此人工智能训练过程中需不断探索和扩展最战略知识前沿。瑕疵信息:不同于国际象棋或围棋那种一览无余的状态,星际玩家无法直接观察到重要信息,必须积极探索“探路”。长期规划:和许多现实世界中的问题并非是从“因”立即生“果”一样,游戏是可以从任何一个地方开始,需要1个小时时间出结果,这意味着在游戏开始时的行动可能在很长一段时间不会有收效。即时性:不像传统桌面游戏,玩家轮流行动,星际玩家必须在游戏时间内持续排兵布阵。庞大的行动空间:要同时控制上百个单位及建筑,这就导致了大量的可能性,行动是分级别的,可以被修改和扩张。我们将游戏参数化后,每个时间步骤平均约有10到26个合理行为。
AlphaStar是如何做到跟星际2职业选手对战的呢?
DeepMind表示,对决时,AlphaStar借助原始界面与星际2游戏引擎交流,也就是说,它可以直接观察地图上的我方单位和敌方可见单位,不需要移动摄像头。如果是人类玩家,注意力有限,必须调整摄像头,让它瞄准应该关注的地方。分析AlphaStar游戏能发现,它有一个隐藏的注意力焦点。平均来说,游戏代理每分钟会切换环境约30次,和MaNa、TLO的频率差不多。

AlphaStar玩星际2的过程(图片来源:DeepMind博客)
事实证明,AlphaStar与MaNa和TLO对决时之所以占据上风,主要是因为它的宏观战略、微观战略决策能力更强,靠的并不是超级点击率、超快响应时间。
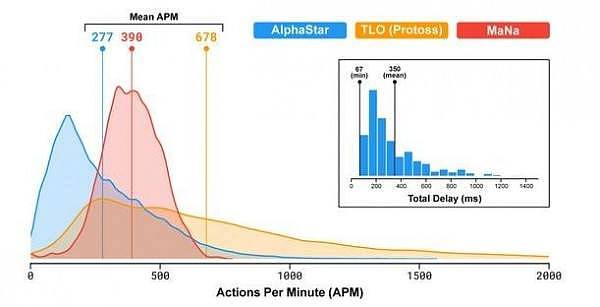
AlphaStar在APM和延迟方面与人类玩家的比较(图片来源:DeepMind博客)
DeepMind还表示,团队的一些训练方法或可有助于研究开发安全稳定的人工智能。人工智能的一大挑战是,系统出错的方式各种各样。先前,星际2的职业玩家可以通过各种新颖方式诱导代理失误,轻易击败AI系统。AlphaStar采用的基于league模式的创新训练方式,可以找到最可靠、最不容易出错的方式。这一创新方式对改进整体AI系统(尤其是在诸如能源等安全至上、且解决复杂边缘案例十分关键的领域)的安全性和稳定性的前景亦值得期待。
DeepMind去年亏损27亿元


每日经济新闻记者注意到, 《经济学人》曾写过一篇文章讨论此事:
首先就是品牌,DeepMind一直走在人工智能的最前沿,围棋事件更被认为是新一轮人工智能发展的里程碑。这一品牌效应帮助谷歌吸引到了最顶级的AI人才,同时也让投资方对谷歌AI的研究实力有了更多的信心。其次是技术合作和应用。谷歌可以直接将DeepMind的技术加入到旗下产品中,并快速向全球消费者输出。最新的案例是,DeepMind的语音合成系统WaveNet的升级版本正被用于在各个平台上生成谷歌语音助手(Google Assistant)的声音。此外,DeepMind此前也宣布,通过使用其最新的算法,为谷歌数据中心节能了15%——这相当于节省了数百万美元的开销。
而Deepmind可以称得上是英美合作案例,结合了英国的研究实力和美国的资本与市场;也可以说是英国人烧美国人的钱做研究,最后共享成果。









 +61
+61 +86
+86 +886
+886 +852
+852 +853
+853 +64
+64


